
Alright, let’s talk about this thing – deadlock stats. It’s one of those topics that sounds a bit intimidating, right? Like something only the super brainy database gurus would mess with. But honestly, I found myself needing to peek into this stuff not too long ago, and it wasn’t as bad as I thought.

Why I Even Bothered
So, things were acting weird. You know the feeling. Random slowdowns, processes hanging, users starting to grumble. My first thought wasn’t immediately “deadlocks!” I went through the usual suspects: checking server load, looking at slow queries, the basic stuff. But nothing really jumped out as the single smoking gun. It felt more like something… tangled.
A colleague, a bit more seasoned than me, casually mentioned, “Hey, ever checked your deadlock stats?” And I was like, “Uhh, nope. Sounds complicated.” But the seed was planted. I figured, what have I got to lose? If the system is already acting up, a little bit of digging isn’t going to make it worse, hopefully.
Figuring Out How to See ‘Em
My first step was, well, trying to remember if I’d ever even seen a command or a screen for this. I poked around in our monitoring tools, but they didn’t give the nitty-gritty I suspected I needed. So, I hit up some internal docs we have – you know, those wikis that someone started with good intentions and then got half-finished. After a bit of searching and trying a few keywords, I found some hints. It wasn’t a shiny button; it was more about querying some system tables or using some specific diagnostic commands.
I remember trying a couple of things that just spat out errors or nothing at all. Classic. You type something in, hit enter, and… crickets. Or worse, a screen full of red text. But eventually, I landed on the right incantation. For our setup, it involved looking at some specific system views that log these events. No fancy UI, just raw data.
The Actual Process of Getting the Data
Once I had the command, or rather, the query, I ran it. I made sure to run it during a period when we suspected these issues were happening, but also when the system wasn’t totally on fire, so I wouldn’t add to the chaos. The first time, the output was just… a lot. A wall of text and numbers. It wasn’t pretty.
My main goal was to find a few things:
- How often were these deadlocks happening? Once a day? Ten times an hour?
- What objects were involved? Were it the same database tables or procedures causing the ruckus every time?
- What were the actual bits of code, the queries, that were locking horns?
I basically copied the output into a text editor. Yeah, super high-tech, I know. Then I started to just visually scan it, looking for patterns. I was looking for repeated table names, similar query structures, that sort of thing. Sometimes I’d filter it a bit, maybe look for entries from just the last few hours.
What I Actually Found in Those Stats
It took a bit of staring, but patterns did emerge. It wasn’t one single thing, of course, that would be too easy. But I did find a couple of stored procedures that seemed to show up a lot in these deadlock reports. And they often involved a specific set of tables related to user session updates and order processing. Aha! A clue!
The stats themselves gave me timestamps, the process IDs involved, the exact SQL statements that were the victims and the ones that were, well, let’s say the “winners” in the deadlock. It also showed what kind of locks they were trying to get. It was like reading a very dry, very technical crime scene report.
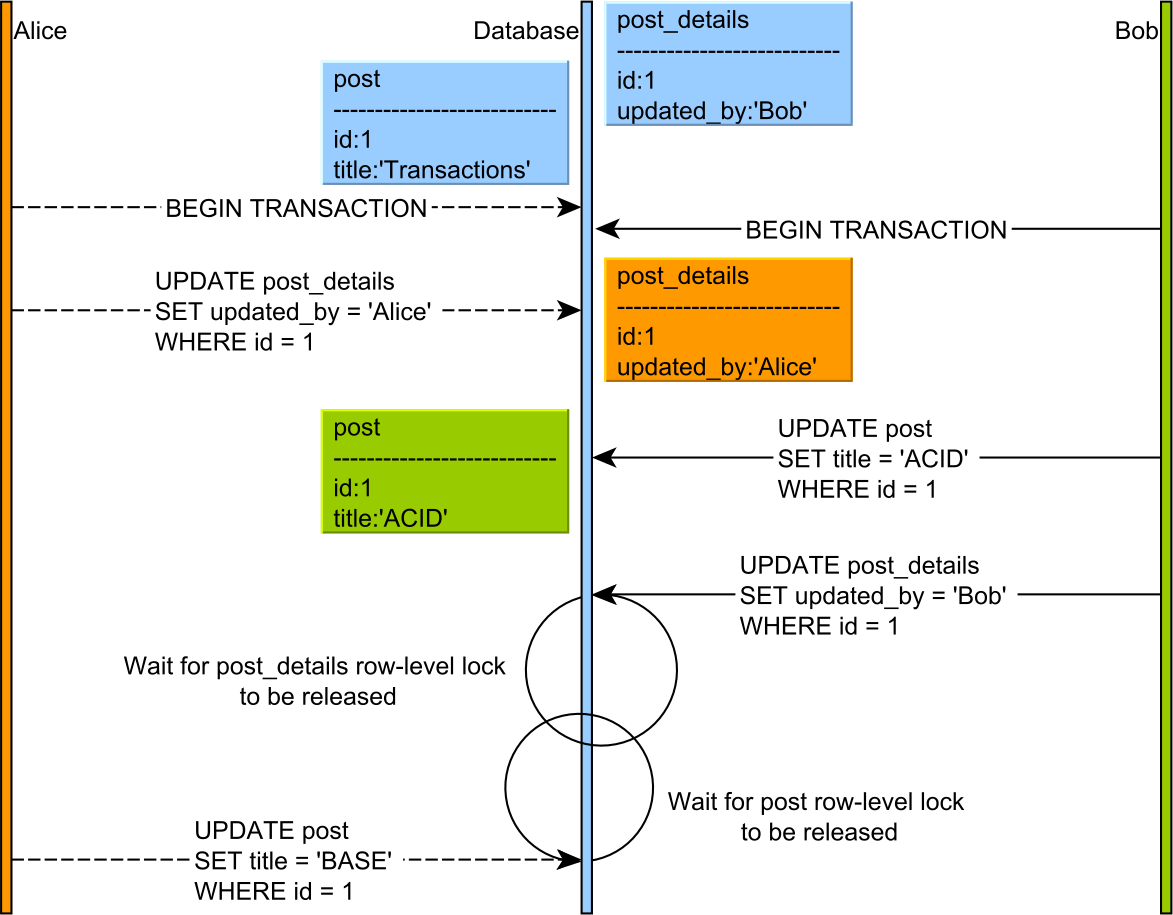
For instance, I saw Process A trying to update Table X then Table Y, while Process B was trying to update Table Y then Table X. Classic standoff. The stats showed me exactly this. It wasn’t just a guess anymore; I had the evidence right there.

What Came Out of It
Armed with this info, I could go back to the development team not just with “hey, things are slow,” but with “hey, it looks like these specific procedures, when they run around the same time, are often deadlocking on these tables. Here’s the proof from the logs.”
It didn’t magically fix everything overnight. But it gave us concrete places to start looking. We could then analyze those specific procedures. Were the transactions too long? Could we change the order of operations? Could we add better indexing to speed things up so they didn’t overlap as much? These deadlock stats were the starting point for those more targeted investigations.
It definitely made me feel a bit more in control, knowing I could pull this kind of information out when things got weird. It’s another tool in the toolbox. Not something I look at every day, but super valuable when you need it. So yeah, that was my little adventure into the world of deadlock stats. Not so scary after all, just a bit of digging.














{kind=link}