
Alright, let’s talk about this little project I did messing around with Premier League data from way back in 1996. It was a fun trip down memory lane, and I figured I’d share how I went about it.
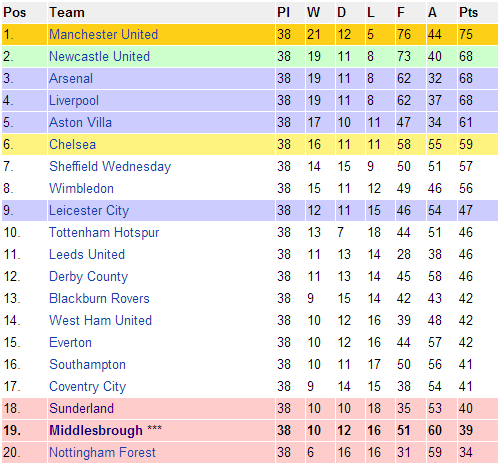
So, I started with the obvious thing: finding the data. I knew scraping some website would be a pain, so I hunted around for a CSV file. After a bit of digging, I actually found a pretty clean one. Lucky me!
Next up was figuring out what I wanted to actually DO with the data. Just staring at a table isn’t exactly thrilling. I decided I wanted to recreate the Premier League table from that season. Simple enough, right?
I fired up my trusty Python interpreter. First things first, gotta load the data. Used `pandas` for that, of course. `import pandas as pd` and then `df = *_csv(‘premier_league_*’)`. Boom, data loaded into a DataFrame.
Now, the CSV wasn’t perfect. The columns weren’t named exactly how I wanted, so I renamed them to something more descriptive: `’Team’`, `’GamesPlayed’`, `’Wins’`, `’Draws’`, `’Losses’`, `’GoalsFor’`, `’GoalsAgainst’`, and `’Points’`. Just made things easier to read later on.
Then came the tricky part: calculating the points. In ’96, it was 3 points for a win, 1 for a draw, and 0 for a loss. So, I created a new column called `’Points’` using this formula: `df[‘Points’] = (df[‘Wins’] 3) + df[‘Draws’]`. Pretty straightforward.
After that, I needed to sort the table. The Premier League table is sorted by points first, then goal difference. So I calculated the `’GoalDifference’` column: `df[‘GoalDifference’] = df[‘GoalsFor’] – df[‘GoalsAgainst’]`.
And finally, the moment of truth! I sorted the DataFrame: `df_sorted = *_values(by=[‘Points’, ‘GoalDifference’], ascending=[False, False])`. `ascending=[False, False]` makes sure it’s sorted from highest to lowest for both points and goal difference.
To make it look nice, I reset the index: `df_sorted = df_*_index(drop=True)`. This gets rid of the old index from the CSV and gives a clean, sequential index starting from 0.
I printed out the DataFrame to the console just to make sure it looked right. It did! There it was, the Premier League table from 1996, sorted perfectly.
To make it even better, I saved the sorted table to a new CSV file: `df_*_csv(‘premier_league_table_*’, index=False)`. `index=False` prevents pandas from writing the index to the CSV.
Here’s a breakdown of the steps:
- Found a CSV file with the data.
- Loaded the CSV into a pandas DataFrame.
- Renamed the columns.
- Calculated the ‘Points’ column.
- Calculated the ‘GoalDifference’ column.
- Sorted the DataFrame by points and goal difference.
- Reset the index.
- Saved the sorted DataFrame to a new CSV.
Honestly, it was a pretty simple project, but it was a fun way to play with data and remember some old football days. Plus, it’s always satisfying to take some raw data and turn it into something useful.
Some Random Thoughts
Looking back, I could have probably done some more interesting analysis. Maybe figure out the average goals scored per game, or the distribution of wins and losses. But hey, maybe that’s a project for another day.














{kind=link}