
Alright, let’s talk about getting those `mae stats` sorted. I found myself needing these numbers recently because, frankly, things felt a bit off with one of our processes, but I didn’t have the hard data to back it up.
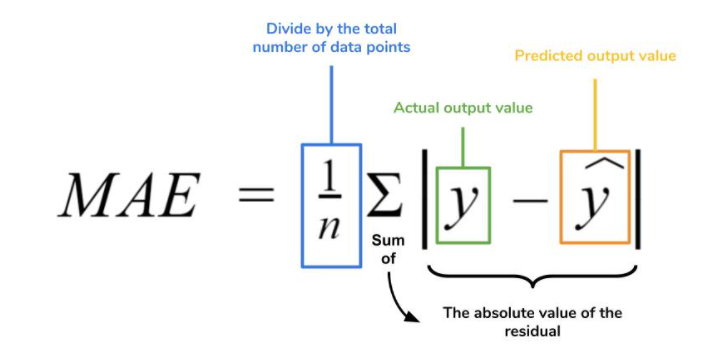
Starting Point: Gut Feeling vs. Numbers
You know how it is, you look at the results day after day, and you get a sense that the error rate is creeping up, or maybe it’s higher than what we initially expected. That was me. I had this nagging feeling, but pointing fingers or even just raising a flag without solid numbers? Not really my style, and it doesn’t help anyone fix the real issue.
So, I decided I needed to dig in and get the actual statistics. Just saying “it feels wrong” wasn’t going to cut it. I needed the average errors, maybe see how they trended over the last few runs.
The Digging Process
First off, I checked the usual places. Looked through the standard reports, the dashboards we have. Nothing quite gave me the specific aggregated error view I was looking for. Lots of raw data, sure, but wading through logs manually? No thanks, not if I could avoid it. Been there, done that, takes forever.
My next thought was, okay, maybe I need to whip up a quick script. Pull the raw data, clean it up, calculate the averages myself. I started outlining it, thinking about parsing the output files. But honestly, it felt like reinventing the wheel. Surely there had to be an easier way?
So, I took a step back. Went through the documentation again, this time looking specifically for anything related to performance summaries or error aggregation. And guess what? Tucked away, there was mention of a specific flag or a utility function I’d completely overlooked before. It wasn’t obvious, mind you, the naming was a bit weird.
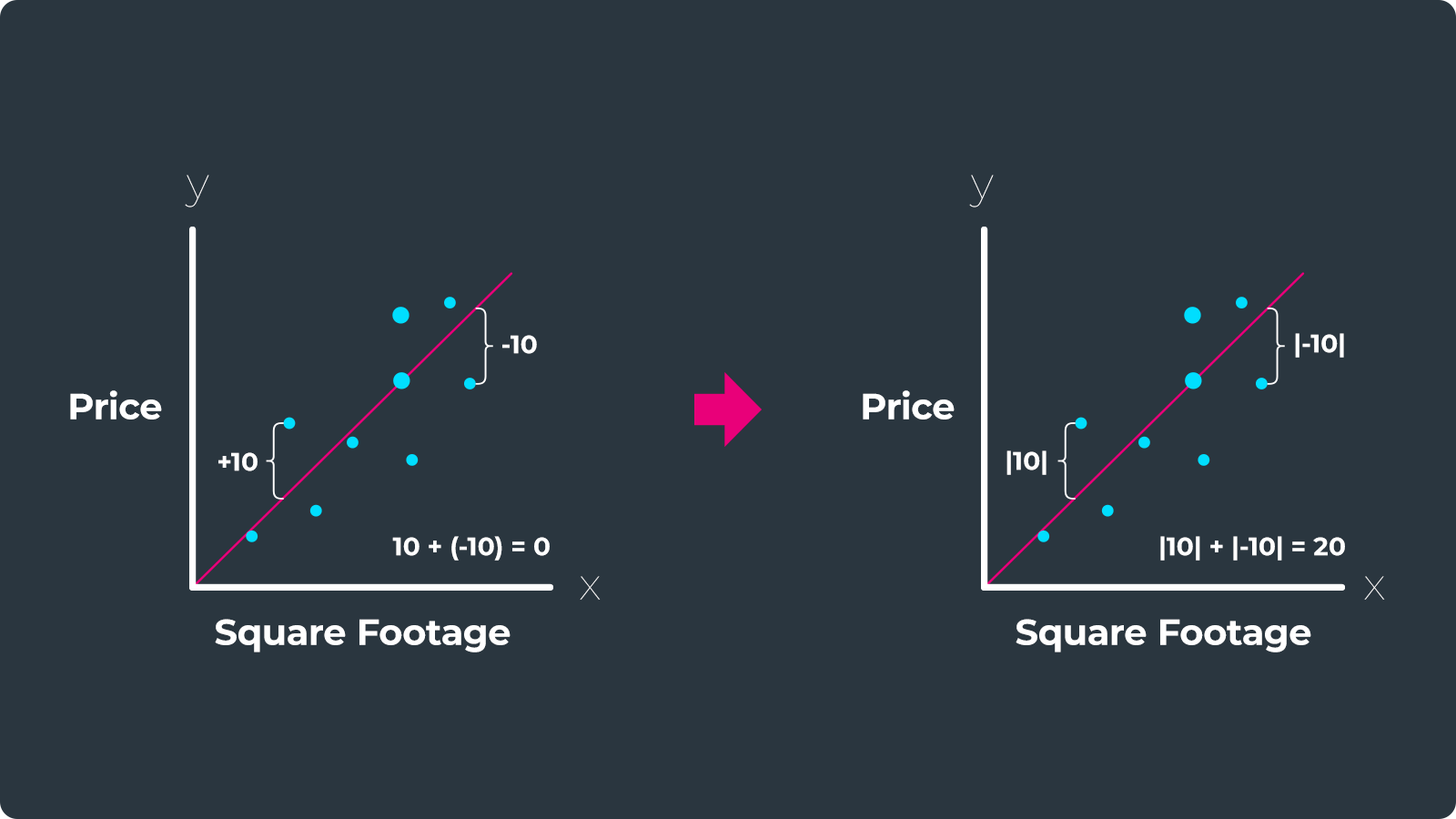
I gave it a try. Ran the process with the specific command argument. It took a bit longer to finish, which made sense because it was doing extra calculations.
Getting the Actual Stats
And boom! At the end of the run, it spat out exactly what I needed. Not just raw logs, but a neat little summary.
Here’s basically what I got:
- The overall average error rate for the entire batch.
- A breakdown of errors by category (this was super helpful).
- The standard deviation, giving me an idea of how wild the errors were.
It wasn’t fancy, just plain text output, but it was the solid data I was missing. Seeing the numbers laid out confirmed my gut feeling – the error rate had increased, especially in one specific category.
Having these `mae stats` made the next conversation so much easier. Instead of saying “I think there’s a problem,” I could say, “Look, the average error rate is X, and it’s mainly coming from category Y. We should focus our attention there.” Made all the difference.

So yeah, sometimes the data you need is hiding in plain sight, just gotta know where to look or what switch to flip. Saved me a bunch of time writing custom scripts this time around.













{kind=link}